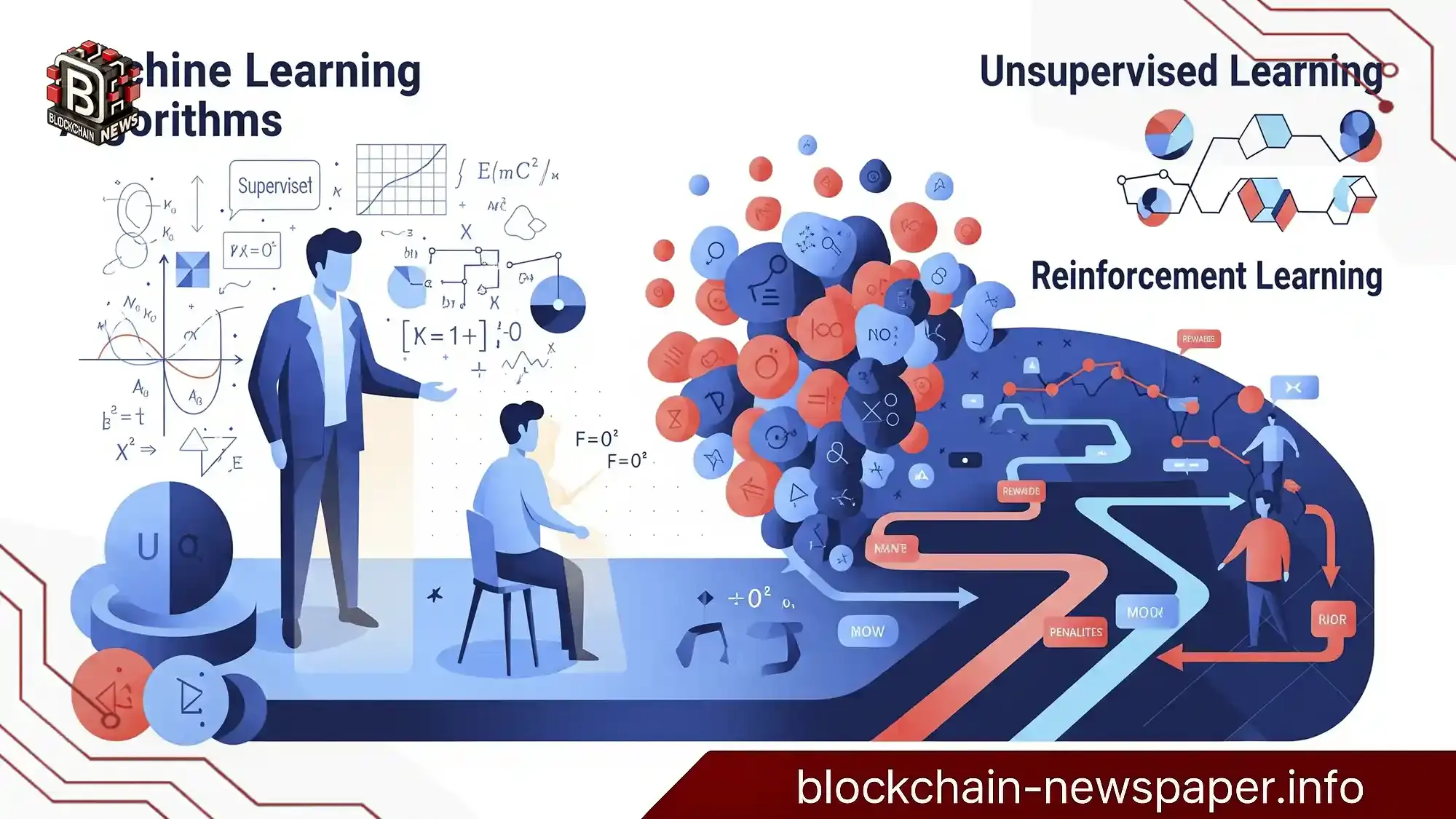
الگوریتمهای یادگیری ماشین چیست؟ بررسی کامل انواع یادگیری نظارتشده، بدوننظارت و تقویتی
با این مقاله جامع با انواع الگوریتمهای یادگیری ماشین آشنا شوید؛ از مدلهای نظارتشده و بدوننظارت گرفته تا یادگیری تقویتی.

با این مقاله جامع با انواع الگوریتمهای یادگیری ماشین آشنا شوید؛ از مدلهای نظارتشده و بدوننظارت گرفته تا یادگیری تقویتی.
جدول محتوا [نمایش]
در دنیای دادهمحور امروز، یادگیری ماشین (Machine Learning) به یکی از پایههای اصلی هوش مصنوعی تبدیل شده است. از تحلیل رفتار کاربران در شبکههای اجتماعی گرفته تا سیستمهای توصیهگر، خودروهای خودران و تشخیص بیماریها، همگی به لطف الگوریتمهای یادگیری ماشین امکانپذیر شدهاند. اما سؤال مهم اینجاست: الگوریتمهای یادگیری ماشین دقیقاً چیستند و چگونه کار میکنند؟
مطالعه آموزش هوش مصنوعی در بلاکچین نیوزپیپر
پیشنهاد مطالعه : تفاوت هوش مصنوعی (AI)، یادگیری ماشین (ML) و یادگیری عمیق (DL) چیست؟
الگوریتمهای یادگیری ماشین در واقع مجموعهای از دستورالعملها و فرمولها هستند که به سیستمها امکان میدهند با تحلیل دادهها، الگوهای پنهان را کشف کرده و بدون برنامهنویسی صریح، تصمیمگیری یا پیشبینی انجام دهند. این الگوریتمها به ماشینها «یاد میدهند» تا از تجربیات گذشته خود (یعنی دادهها) بیاموزند و در مواجهه با دادههای جدید، عملکردی هوشمندانهتر داشته باشند.
یکی از نکات کلیدی در یادگیری ماشین، درک انواع مختلف یادگیری است؛ چرا که هر نوع از الگوریتمها، ساختار، کاربرد و محدودیتهای خاص خود را دارند. بر همین اساس، یادگیری ماشین بهطور کلی به سه دسته اصلی تقسیم میشود:
یادگیری نظارتشده (Supervised Learning): زمانی که دادههای آموزشی دارای خروجی مشخص (برچسب) هستند.
یادگیری بدوننظارت (Unsupervised Learning): زمانی که دادهها فقط شامل ویژگیها هستند و خروجی مشخصی ندارند.
یادگیری تقویتی (Reinforcement Learning): الگوریتمهایی که از طریق تعامل با محیط و دریافت پاداش، یاد میگیرند چگونه رفتار بهینه را بیاموزند.
شناخت تفاوتها و کاربردهای هر یک از این روشها، برای دانشجویان، پژوهشگران، توسعهدهندگان و مدیران کسبوکار، حیاتی است. چرا که انتخاب الگوریتم مناسب، نهتنها دقت و کارایی مدل را افزایش میدهد، بلکه منابع پردازشی را بهدرستی مدیریت کرده و باعث صرفهجویی در زمان و هزینه میشود.

یادگیری نظارتشده یکی از متداولترین و کاربردیترین روشهای یادگیری ماشین است. در این نوع یادگیری، مدل با استفاده از دادههای برچسبخورده (Labelled Data) آموزش میبیند؛ یعنی برای هر ورودی، خروجی صحیح مشخص است.
مدل در طول فرآیند آموزش یاد میگیرد که چگونه ورودیها را به خروجیهای صحیح مرتبط کند. پس از آموزش، میتواند برای دادههای جدید، خروجی مناسب پیشبینی کند.
مثال ساده: فرض کنید مجموعهای از دادهها شامل ویژگیهای یک خانه (متراژ، موقعیت، تعداد اتاق) و قیمت نهایی آن باشد. الگوریتم یاد میگیرد که رابطهای بین این ویژگیها و قیمت وجود دارد و سپس میتواند برای خانههای جدید قیمت را تخمین بزند.
یادگیری نظارتشده در حوزههای بسیار گستردهای مورد استفاده قرار میگیرد:
تشخیص ایمیلهای اسپم (Spam Detection)
پیشبینی فروش یا قیمت کالاها
تشخیص بیماری بر اساس علائم پزشکی یا نتایج آزمایشها
تحلیل احساسات کاربران در شبکههای اجتماعی
طبقهبندی تصاویر در بینایی ماشین
طبقهبندی (Classification):
زمانی که خروجی مدل، یک دسته (Class) مشخص است.
مثال: ایمیل اسپم یا غیر اسپم، تصویری از گربه یا سگ.
رگرسیون (Regression):
زمانی که خروجی مدل، یک مقدار عددی پیوسته است.
مثال: پیشبینی قیمت خانه یا میزان بارندگی.
مدل پایهای برای پیشبینی مقادیر عددی
مناسب برای مسائل رگرسیون ساده
خروجی پیوسته تولید میکند
کاربرد: پیشبینی قیمت، تقاضا، روندها
با وجود نام مشابه، برای طبقهبندی استفاده میشود
خروجی بهصورت احتمال تعلق به کلاس خاص است
کاربرد: تشخیص بیماری، اسپم، بله/خیر
الگوریتم گرافیکی بر پایه شرطها
تفسیرپذیر و قابل فهم برای انسان
کاربرد: تحلیل مشتریان، فیلترهای مالی
مجموعهای از درختهای تصمیم که رأیگیری میکنند
دقت بالا، مقاومت در برابر بیشبرازش (Overfitting)
کاربرد: پیشبینیهای دقیق در دادههای پیچیده
الگوریتمی قدرتمند برای طبقهبندی با مرزهای واضح
عملکرد خوب در دادههای با ابعاد بالا
کاربرد: تشخیص چهره، متن، تصاویر
الگوریتم ساده ولی مؤثر بر اساس فاصله بین دادهها
نیاز به ذخیرهسازی کل دادهها (پردازش سنگین در تست)
کاربرد: دستهبندی متون یا مشتریان
مبتنی بر احتمال و قضیه بیز
سریع و مناسب برای دادههای متنی یا اسپم
فرض استقلال ویژگیها (که در عمل همیشه دقیق نیست)
دقت بالا در شرایط کنترلشده
آموزش و تفسیر آسان در مدلهای ساده
کاربرد گسترده در صنعت، تجارت، پزشکی و...
نیاز به حجم بالایی از دادههای برچسبخورده
عملکرد محدود در مواجهه با دادههای پیچیده یا بدون ساختار
مستعد بیشبرازش در مدلهای پیچیده یا دادههای کوچک
فرض کنید دادههای مربوط به بیماران شامل علائم مختلف (تب، فشارخون، آزمایش خون) و وضعیت نهایی (بیمار یا سالم) در اختیار دارید.
با آموزش یک مدل یادگیری نظارتشده (مثلاً درخت تصمیم یا Logistic Regression)، میتوانید برای بیمار جدید با علائم مشابه، وضعیت سلامت او را پیشبینی کنید.
اگر داده کم و ساده است: KNN یا Naive Bayes
اگر داده پیچیده ولی برچسبخورده دارید: SVM یا Random Forest
اگر نیاز به تفسیر دارید: درخت تصمیم یا رگرسیون لجستیک
اگر هدف دقت است و منابع کافی دارید: جنگل تصادفی یا ترکیبی (Ensemble)
یادگیری نظارتشده نقطه شروع بسیاری از پروژههای یادگیری ماشین است. این روش با کمک دادههای برچسبدار، به مدل اجازه میدهد تا روابط موجود در داده را شناسایی کرده و بر اساس آن، پیشبینی یا طبقهبندی انجام دهد. با شناخت درست از انواع الگوریتمهای موجود، میتوان مدلهایی دقیق، سریع و قابل تفسیر توسعه داد.

یادگیری بدوننظارت (Unsupervised Learning) نوعی از یادگیری ماشین است که در آن، دادهها بدون برچسب خروجی به مدل داده میشوند. در این روش، الگوریتم تلاش میکند ساختار پنهان یا الگوهای موجود در دادهها را کشف کند، بدون آنکه از قبل بداند خروجی درست چیست.
هدف این دسته از یادگیری، تقسیمبندی دادهها، کشف روابط و خوشهبندی (Clustering) یا کاهش ابعاد (Dimensionality Reduction) برای درک بهتر دادههاست.
تحلیل مشتریان و خوشهبندی آنها در بازاریابی (Customer Segmentation)
کشف تقلب در تراکنشهای مالی
تحلیل شبکههای اجتماعی و گروهبندی کاربران
فشردهسازی و کاهش ابعاد دادهها (مثلاً در تصاویر یا ژنومها)
تشخیص ناهنجاریها در دادههای صنعتی یا امنیتی
سادهترین و پراستفادهترین الگوریتم
دادهها را به K دسته تقسیم میکند
نیاز به تعیین تعداد خوشهها از قبل
کاربرد: گروهبندی مشتریان، دستهبندی سندها
بدون نیاز به تعیین تعداد خوشه در ابتدا
ایجاد ساختار درختی (دندروگرام) برای نمایش ارتباط بین دادهها
کاربرد: ژنتیک، زیستدادهها، بازارها
الگوریتم مبتنی بر چگالی دادهها
میتواند ناهنجاریها (نویزها) را تشخیص دهد
مناسب برای دادههای پیچیده با اشکال نامنظم
کاربرد: تشخیص نقاط غیرعادی، تحلیل زمینشناسی
تبدیل دادههای چندبعدی به فضایی با ابعاد کمتر
حفظ بیشترین میزان اطلاعات در کمترین ابعاد
کاربرد: فشردهسازی دادهها، پیشپردازش برای مدلسازی
کشف الگوهای هموقوع در دادهها
کاربرد: سبد خرید مشتریان، تحلیل رفتار کاربر
عدم نیاز به دادههای برچسبخورده (صرفهجویی در هزینه و زمان)
کشف ساختارهای پنهان و روابط ناشناخته در داده
مناسب برای تحلیل دادههای بزرگ و اکتشافی
تفسیر نتایج میتواند دشوار باشد
نبود خروجی مرجع باعث ارزیابی نسبی مدل میشود
وابسته به پارامترهای حساس مثل تعداد خوشه یا چگالی
امکان ایجاد خوشههای نادرست در صورت دادههای پراکنده
فرض کنید یک فروشگاه، اطلاعات خرید مشتریان را جمعآوری کرده ولی نمیداند کدام دسته مشتری علاقهمند به کدام گروه کالاها هستند. با استفاده از الگوریتم K-Means یا DBSCAN میتوان مشتریان را به چند خوشه تقسیم کرد (مثلاً مشتریان وفادار، تخفیفمحور، مناسب فصول خاص)، و سپس کمپین بازاریابی هدفمند برای هر خوشه طراحی نمود.
همیشه قبل از اعمال الگوریتم، تحلیل اکتشافی دادهها (EDA) انجام دهید.
نرمالسازی و مقیاسگذاری دادهها (مثلاً با StandardScaler) برای بسیاری از الگوریتمها ضروری است.
برای ارزیابی مدل از شاخصهایی مثل Silhouette Score، Davies-Bouldin Index یا بصریسازی (t-SNE، UMAP) استفاده کنید.
برخی الگوریتمها (مثل DBSCAN) در برابر نویز مقاوماند و نیاز به تنظیمات دقیق دارند.
یادگیری بدوننظارت بهعنوان ابزاری قدرتمند برای کشف الگوهای ناشناخته و ساختارهای پنهان در دادهها، نقش حیاتی در تحلیل اکتشافی، بازاریابی، زیستدادهها و امنیت دارد. این نوع الگوریتمها به سیستمها اجازه میدهند بدون راهنمایی مستقیم، بینشهایی از داده استخراج کنند که ممکن است برای انسان نامرئی باشد.

یادگیری تقویتی (Reinforcement Learning – RL) شاخهای از یادگیری ماشین است که با الهام از شیوه یادگیری انسان و حیوانات، بر پایه تجربه، آزمونوخطا و پاداش عمل میکند.
در این مدل، یک عامل (Agent) در یک محیط (Environment) عمل میکند، از طریقهٔ عملکرد خود پاداش (Reward) یا تنبیه دریافت میکند و بهمرور یاد میگیرد که چه رفتاری بیشترین پاداش را کسب میکند.
این نوع یادگیری برخلاف روشهای نظارتشده و بدوننظارت، نیازی به دادههای آماده ندارد، بلکه مدل خودش با تعامل فعال با محیط، به دانش میرسد.
عامل (Agent): موجودی که تصمیم میگیرد چه کاری انجام دهد (مثلاً ربات، نرمافزار، هوش بازی).
محیط (Environment): دنیایی که عامل در آن قرار دارد و با آن تعامل میکند.
وضعیت (State): نمایانگر شرایط فعلی عامل در محیط.
عمل (Action): کارهایی که عامل میتواند در هر وضعیت انجام دهد.
پاداش (Reward): بازخورد محیط به اقدام عامل؛ مثبت یا منفی.
سیاست (Policy): راهبردی که مشخص میکند عامل در هر وضعیت چه عملی انجام دهد.
تابع ارزش (Value Function): میزان ارزش یک وضعیت در بلندمدت (بر اساس پاداشهای آتی).
مدل محیط (Model): گاهی در برخی الگوریتمها از یک مدل برای پیشبینی وضعیت آینده استفاده میشود.
بازیها: شکست دادن انسان در بازیهایی مانند شطرنج، Go (مثلاً AlphaGo)، StarCraft
رباتیک: آموزش حرکات پیچیده به رباتها (مثلاً راه رفتن، گرفتن اشیاء)
مالی: بهینهسازی پورتفوی سرمایهگذاری یا معاملات خودکار
خودروهای خودران: تصمیمگیری لحظهای در محیطهای متغیر
مدیریت منابع: کنترل مصرف انرژی در مراکز داده، تخصیص هوشمند منابع در شبکهها
یکی از سادهترین و مشهورترین الگوریتمها
بدون نیاز به مدل از محیط
با استفاده از یک جدول (Q-Table) وضعیتها و اعمال را ارزشگذاری میکند
مناسب برای محیطهای ساده و قابل شمارش
شبیه Q-Learning اما با بهروزرسانی بر اساس سیاست فعلی
بیشتر به اکتشاف ادامه میدهد
رفتار «محافظهکارانهتری» نسبت به Q-Learning دارد
نسخه پیشرفته Q-Learning با استفاده از شبکههای عصبی برای تخمین Q-Value
مناسب برای محیطهای بزرگ و پیچیده
مورد استفاده در پروژههایی مانند بازی آتاری توسط DeepMind
بهجای یادگیری ارزش وضعیتها، مستقیماً سیاست را یاد میگیرد
مناسب برای مسائل پیوسته یا چندبعدی
با استفاده از مشتقات ریاضی، سیاست را در جهت افزایش پاداش بهینه میکند
ترکیبی از Policy Gradient و Value Function
دارای دو بخش: Actor (انتخاب عمل) و Critic (ارزیابی عمل)
کارایی و پایداری بالاتری نسبت به مدلهای صرفاً Actor یا Critic دارد
مناسب برای مسائل پویا، متوالی و وابسته به زمان
نیازی به داده برچسبخورده ندارد
قدرت یادگیری در محیطهای ناشناخته
قابلیت یادگیری از تجربه و سازگاری با شرایط جدید
آموزش بسیار زمانبر و منابعبر
احتمال نوسان در یادگیری و همگرایی دشوار
نیاز به تنظیم دقیق پارامترها (مثل نرخ یادگیری، تخفیف پاداش و...)
چالشهای اخلاقی در کاربردهای پرریسک (مانند رانندگی خودکار)
فرض کنید رباتی میخواهید بسازید که بتواند راه برود. شما به آن نمیگویید «دقیقاً چه حرکتی» انجام دهد. فقط هر بار که قدمی موفق برداشت، به آن پاداش میدهید. ربات با آزمونوخطا، بهمرور یاد میگیرد که چه توالی حرکاتی باعث گرفتن بیشترین پاداش میشود. این دقیقاً مفهوم یادگیری تقویتی است.
یادگیری تقویتی درک تازهای از «هوش پویا» ارائه میدهد. برخلاف مدلهایی که تنها دادههای ایستا را تحلیل میکنند، RL به عامل اجازه میدهد تا از تجربه، بازخورد و تعامل با محیط، راهبرد بهینهای را یاد بگیرد. همین ویژگی باعث شده تا یادگیری تقویتی در صدر تکنولوژیهای آیندهساز مانند رباتیک، بازیسازی، کنترل هوشمند و مالی قرار گیرد.
درک تفاوت میان انواع یادگیری ماشین، فقط جنبه علمی ندارد؛ بلکه در انتخاب درست الگوریتم، صرفهجویی در منابع، افزایش دقت مدل و موفقیت پروژههای عملی نقش کلیدی ایفا میکند.
| ویژگی | یادگیری نظارتشده (Supervised) | یادگیری بدوننظارت (Unsupervised) | یادگیری تقویتی (Reinforcement) |
|---|---|---|---|
| ورودی داده | برچسبخورده (Labelled) | بدون برچسب | تعامل با محیط |
| هدف | پیشبینی یا طبقهبندی خروجی | کشف الگوها یا خوشهها | حداکثرسازی پاداش از طریق تجربه |
| خروجی مدل | دستهبندی یا مقدار عددی | گروهبندی، کاهش ابعاد | سیاست بهینه برای تصمیمگیری |
| نحوه آموزش | بر اساس دادههای صحیح | بدون خروجی مرجع | بر اساس پاداش/تنبیه محیط |
| وابستگی به داده آماده | بالا | کمتر | نیاز به محیط شبیهسازیشده |
| پیچیدگی زمانی | متوسط | متوسط | بالا (زمانبر) |
| تفسیرپذیری | بالا تا متوسط | پایین تا متوسط | پایین (در مدلهای پیچیده) |
| حوزه کاربرد | Supervised | Unsupervised | Reinforcement |
|---|---|---|---|
| پزشکی | تشخیص بیماری از داده آزمایش | گروهبندی بیماران بر اساس علائم | آموزش ربات جراحی برای دقت بهتر |
| بازار و فروش | پیشبینی قیمت یا فروش | تحلیل رفتار خرید مشتری | تنظیم خودکار تخفیفها در لحظه |
| امنیت | تشخیص تقلب در تراکنشها | کشف الگوهای ناهنجار | آموزش فایروال تطبیقی برای واکنش بهتر |
| آموزش | طبقهبندی سطوح دانشآموزان | خوشهبندی بر اساس سبک یادگیری | تطبیق محتوای درسی در لحظه |
| رباتیک و کنترل | تشخیص اشیا از تصویر | خوشهبندی محیطها | آموزش ربات برای حرکت یا گرفتن اشیا |
| نوع یادگیری | مزایا | چالشها |
|---|---|---|
| نظارتشده | دقت بالا، پیادهسازی ساده، ارزیابی روشن | نیاز به دادههای برچسبخورده، خطر بیشبرازش |
| بدوننظارت | بدون نیاز به برچسب، کشف ساختار پنهان | تفسیر سخت، ارزیابی نتایج نسبی |
| تقویتی | توانمندی در تصمیمگیری پویا، سازگاری با محیط | آموزش زمانبر، نیاز به آزمون زیاد، منابع بالا |
| شرایط پروژه | نوع یادگیری پیشنهادی |
|---|---|
| دادههای دقیق و برچسبخورده دارید | یادگیری نظارتشده |
| دادههای خام و گسترده دارید | یادگیری بدوننظارت |
| محیط پویا دارید و نیاز به تصمیمگیری مرحلهای دارید | یادگیری تقویتی |
| زمان آموزش محدود دارید | یادگیری نظارتشده یا بدوننظارت |
| پروژه در حوزه بازیسازی، رباتیک یا سیستمهای واکنشمحور است | یادگیری تقویتی |
سه نوع یادگیری ماشین — نظارتشده، بدوننظارت و تقویتی — هر یک برای شرایط، دادهها و اهداف خاصی طراحی شدهاند. استفاده درست از آنها، مستقیماً به موفقیت پروژههای هوش مصنوعی در دنیای واقعی منجر میشود. مقایسه ساختاری و عملی، نهتنها به انتخاب بهتر کمک میکند، بلکه مانع از صرف وقت و هزینه اضافی در مسیرهای نادرست میشود.

یادگیری ماشین به نقطهای رسیده که دیگر فقط یک ابزار علمی نیست؛ بلکه به نیروی پیشران کسبوکارها، خدمات عمومی، سلامت، و حتی تولید محتوا تبدیل شده. اما آینده چه در چنته دارد؟ در این قسمت نگاهی میاندازیم به روندهای نوظهور، فناوریهای ترکیبی، و مسیرهای آینده الگوریتمهای یادگیری ماشین.
یکی از گرایشهای مهم، ترکیب روشهای مختلف یادگیری برای بهدست آوردن بهترین عملکرد است. نمونههایی از این روشها:
Semi-Supervised Learning: ترکیبی از دادههای برچسبخورده و بدونبرچسب برای آموزش.
Self-Supervised Learning: مدل خودش برچسبسازی میکند (مانند GPT، BERT).
Active Learning: مدل فقط از دادههایی یاد میگیرد که بیشترین ارزش اطلاعاتی دارند.
Few-shot و Zero-shot Learning: آموزش مدلها با دادههای بسیار کم یا بدون آموزش مستقیم.
AutoML یا "یادگیری ماشین خودکار"، روند طراحی و انتخاب الگوریتمهای بهینه را با کمترین دخالت انسانی ممکن میسازد. ویژگیها:
انتخاب خودکار بهترین مدل برای یک داده خاص
تنظیم خودکار هایپرپارامترها
بهینهسازی فرآیند یادگیری برای دقت و سرعت
کاربردی برای کاربران غیرمتخصص در ML
ابزارهای معروف: Google AutoML, H2O.ai, AutoKeras
با دادههایی که بهصورت جریان لحظهای تولید میشوند (مثل شبکههای اجتماعی، سنسورها یا بازار بورس)، یادگیری ماشین باید بتواند در لحظه خود را بهروزرسانی کند.
یادگیری آنلاین امکان بهبود مدل در زمان واقعی (Real-Time) را فراهم میکند.
در حوزههایی مثل IoT، امنیت شبکه، بازارهای مالی و تبلیغات آنی بسیار حیاتی است.
مدلهای آینده باید بتوانند خود را با شرایط محیطی جدید وفق دهند. یادگیری تطبیقی به مدلها این امکان را میدهد که:
در شرایط تغییر توزیع داده (Data Drift) عملکرد خود را حفظ کنند
در محیطهای نامطمئن و پویا (مثل سیستمهای توصیهگر، حملونقل، بازی) سازگار بمانند
بهصورت پویا ساختار یا پارامترهای خود را تنظیم کنند
با گسترش استفاده از الگوریتمها در تصمیمگیریهای حساس، نیاز به تفسیرپذیری و اخلاقپذیری افزایش یافته است.
XAI تلاش میکند تصمیمات مدلها را برای انسان قابل توضیح کند
مدلهای آینده باید شفاف، مسئولانه و بدون سوگیری باشند
چارچوبهای قانونی و استانداردهای بینالمللی برای ML در حال توسعه هستند
در این رویکرد، دادهها در محل خود باقی میمانند و فقط مدلها به اشتراک گذاشته میشوند.
ویژگیها:
حریم خصوصی حفظ میشود
مناسب برای اپلیکیشنهای موبایل، بانکها، مراکز درمانی
کاهش ریسک نشت داده در فرآیند آموزش
آینده یادگیری ماشین نه در تکرار الگوریتمهای فعلی، بلکه در ترکیب هوشمندانه روشها، خودکارسازی فرآیندها، و تفسیر تصمیمات مدلها نهفته است.
الگوریتمهای آینده باید نهتنها دقیق و سریع، بلکه قابل درک، اخلاقی، و سازگار با محیط باشند. یادگیری ماشین بهسوی خودآموزی، همکاری انسانی–ماشینی، و پیادهسازی در زندگی روزمره در حال حرکت است.
آدرس ای میل شما نمایش داده نمیشود.







